A generative model is a type of machine learning model that learns to generate new data that is similar to the data it was trained on. Generative models are used in a variety of applications, including image and video synthesis, natural language processing, and speech recognition.
The goal of a generative model is to learn the underlying distribution of the data it was trained on, and then use this distribution to generate new data that is similar to the original data. There are several types of generative models, including:
- Autoencoders: An autoencoder is a neural network that learns to compress the input data into a lower-dimensional representation, and then reconstruct the original data from this representation. Autoencoders can be used to generate new data by randomly sampling from the lower-dimensional representation and then decoding it back into the original space.
- Variational autoencoders (VAEs): VAEs are a type of autoencoder that are designed to generate new data by sampling from a learned latent space that has a simple distribution (typically a normal distribution). VAEs are often used in image and video synthesis, where they can generate new images or videos by sampling from the learned latent space.
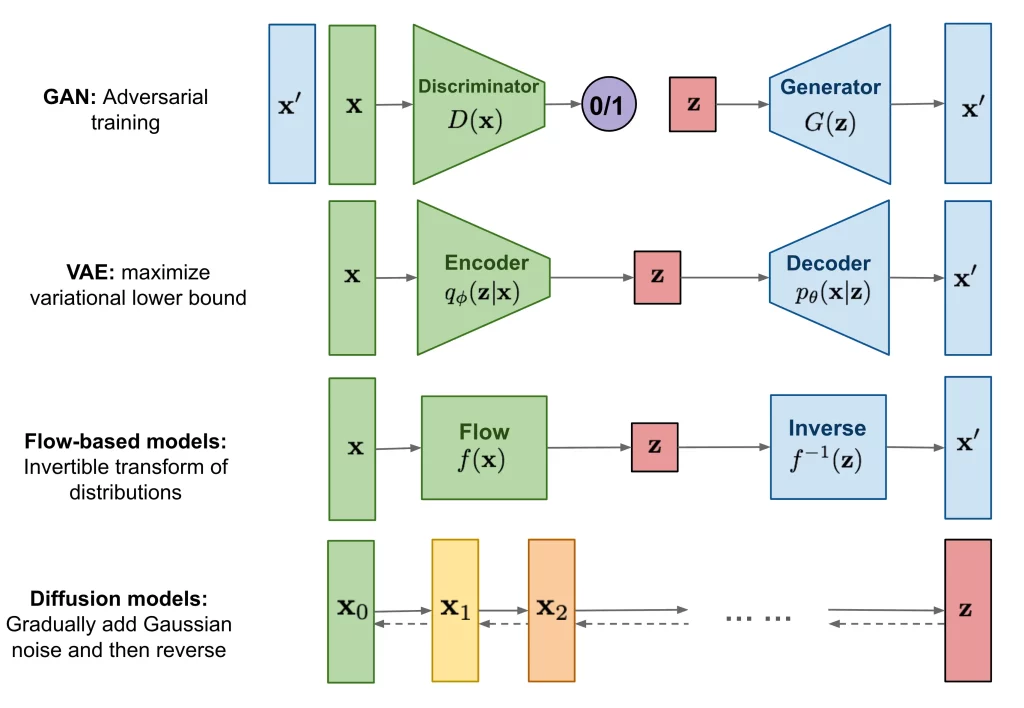
- Generative adversarial networks (GANs): GANs are a type of neural network that consist of two parts: a generator and a discriminator. The generator learns to generate new data that is similar to the original data, while the discriminator learns to distinguish between the generated data and the original data. The generator and discriminator are trained together in a min-max game, where the goal of the generator is to fool the discriminator into thinking that the generated data is real.
- Flow-based models: Flow-based models are a type of generative model that learn to transform a simple distribution (such as a normal distribution) into a more complex distribution that is similar to the original data. Flow-based models are often used in natural language processing, where they can generate new text by sampling from the learned distribution.
- Diffusion generative models: also known as Diffusion Probabilistic Models or DPMs, are a class of generative models that have gained popularity in recent years for their ability to generate high-quality images and videos.
Generative models have a wide range of applications and can be used to generate new data in many different domains.
Autoencoders
Autoencoders are a type of neural network that can learn to compress and reconstruct input data. The basic idea behind autoencoders is to use a neural network to encode the input data into a lower-dimensional representation, and then use another neural network to decode this representation back into the original input space.
The encoding part of the autoencoder is called the encoder, and the decoding part is called the decoder. The encoder typically consists of one or more hidden layers that compress the input data into a lower-dimensional representation, and the decoder consists of one or more hidden layers that reconstruct the input data from this representation.
Autoencoders can be trained using a process called unsupervised learning, which means that they can learn to compress and reconstruct input data without any explicit labels or targets. The training process typically involves minimizing a reconstruction loss function, which measures the difference between the original input data and the reconstructed output data.
One of the key applications of autoencoders is in data compression, where they can be used to reduce the dimensionality of high-dimensional data such as images, videos, and audio signals. By compressing the data into a lower-dimensional representation, autoencoders can reduce the storage requirements and computational complexity of processing the data.
Another application of autoencoders is in generative modeling, where they can be used to generate new data that is similar to the original input data. This is accomplished by sampling from the learned lower-dimensional representation and then decoding the samples back into the original input space.
Autoencoders are a versatile and powerful tool for learning compact representations of input data, and have a wide range of applications in areas such as data compression, generative modeling, and anomaly detection.
Variational Autoencoders (VAEs)
Variational Autoencoders (VAEs) are a type of autoencoder that adds a probabilistic layer to the standard autoencoder architecture. The probabilistic layer in a VAE learns to model the distribution of the latent space, which allows the model to generate new samples by sampling from this distribution.
The key difference between a VAE and a standard autoencoder is that the VAE’s encoder generates two vectors for each input: a mean vector and a variance vector. These vectors are used to define a Gaussian distribution in the latent space, from which we can sample to generate new data points.
The training of a VAE involves two parts: an encoder that maps input data to a distribution in the latent space, and a decoder that maps latent samples back to the input space. During training, the VAE tries to minimize the difference between the input data and the output of the decoder, while also minimizing the difference between the distribution in the latent space and a unit Gaussian distribution. This encourages the VAE to learn a well-formed and well-organized latent space that can be easily sampled from to generate new data.
One of the key benefits of VAEs is that they can be used to generate new data that is similar to the original data, while also exploring the underlying structure of the data. VAEs have been applied to a wide range of applications, including image and video generation, text generation, and drug discovery.
VAEs are a powerful tool for generative modeling and can learn rich and structured latent spaces that can be used to generate new and diverse data samples.
Generative adversarial networks (GANs)
Generative Adversarial Networks (GANs) are a type of neural network architecture used in generative modeling. The idea behind GANs is to have two neural networks play a game, where one network generates samples and the other network tries to distinguish between the generated samples and the real ones. The two networks are trained together in adversarial training, which involves updating the generator to generate better samples, while updating the discriminator to better distinguish between real and generated samples.
The generator in a GAN generates new data samples that are similar to the original data, while the discriminator is responsible for learning to distinguish between real and generated samples. During training, the generator generates a batch of fake samples mixed with a batch of real samples to form a training set for the discriminator. The discriminator is then trained to correctly classify the real and generated samples, and the generator is updated based on the feedback from the discriminator.
The key advantage of GANs is that they can generate new data that is highly realistic and diverse. GANs have generated realistic images, videos, audio, and even 3D objects. GANs have also been used in applications such as data augmentation, image and video synthesis, and image-to-image translation.
One of the challenges of training GANs is that they can be difficult to stabilize and prone to mode collapse, where the generator only learns to generate a small subset of the possible output space. Several techniques have been proposed to address these challenges, including spectral normalization, Wasserstein distance, and attention mechanisms.
GANs are a powerful tool for generative modeling and have enabled a wide range of applications in computer vision, natural language processing, and many other areas.
Flow-based models
Flow-based models are a type of generative model that learn to transform a simple distribution (such as a normal distribution) into a more complex distribution that is similar to the original data. The basic idea behind flow-based models is to define a sequence of invertible transformations that map a simple distribution to the target distribution.
The transformations in a flow-based model are typically designed to be easy to compute and easy to invert so that both sampling from the target distribution and computing the likelihood of a sample can be done efficiently. The flow-based model learns to optimize the parameters of the transformations to maximize the likelihood of the training data.
One of the key advantages of flow-based models is that they can generate new data that is highly realistic and diverse while also allowing for efficient sampling and likelihood computation. Flow-based models have been used to generate realistic images, videos, and text, and have shown promising results in tasks such as density estimation and image synthesis.
One popular type of flow-based model is the Real NVP (Real Non-Volume Preserving) model, which defines a sequence of invertible transformations that split the input data into two parts and transform each part separately. Another popular type of flow-based model is the Glow model, which uses a sequence of invertible 1×1 convolutions and affine transformations to transform the input data.
Flow-based models are a promising area of research that have already demonstrated impressive results in generating realistic data and modeling complex distributions.
Diffusion generative models
Diffusion generative models, also known as Diffusion Probabilistic Models or DPMs, are generative models that have gained popularity in recent years for their ability to generate high-quality images and videos.
The basic idea behind diffusion generative models is to model the generation process as a series of diffusion steps, where the pixels in the image or video are updated in a way that slowly diffuses information from neighboring pixels. At each diffusion step, the model applies random noise to the pixels and updates them based on a learned function that takes into account the current state of the pixels and the noise added at that step.
The diffusion process starts with a noise image. The generative model learns to apply a series of noise-reducing steps to gradually transform the noise image into a high-quality image that looks like a real image. This is accomplished by training the model to maximize the likelihood of the observed data given the noise at each step, using a technique called maximum likelihood estimation.
One of the key advantages of diffusion generative models is their ability to generate high-quality images and videos with a wide range of resolutions and content. They are also computationally efficient since they only need to perform a series of diffusion steps to generate a sample, as opposed to the iterative sampling process required by other generative models like GANs.
Diffusion generative models are a promising area of research that has already demonstrated impressive results in generating realistic images and videos.
Advantages and disadvantages of generative models
I am not an expert in generating models, and these are my personal understanding, and I draw the conclusion from my experience after using each of these models. Here are some advantages and disadvantages of the different types of generative models I explained earlier:
- Autoencoders:
- Advantages: Autoencoders are computationally efficient and can be used for tasks such as data compression, image denoising, and anomaly detection. They are also relatively easy to train and can be trained using unsupervised learning.
- Disadvantages: Autoencoders may not be as effective at generating new data samples as other types of generative models and may not capture the complex distribution of the original data.
- Variational Autoencoders:
- Advantages: VAEs can generate high-quality samples that are similar to the original data, and can explore the structure of the data using the learned latent space. They are also computationally efficient and can be used for a wide range of applications.
- Disadvantages: VAEs can be difficult to train and may suffer from mode collapse, where the generator only learns to generate a small subset of the possible output space.
- Generative Adversarial Networks:
- Advantages: GANs can generate highly realistic and diverse samples and can be used for a wide range of applications such as image synthesis, image-to-image translation, and data augmentation. They are also computationally efficient and can be trained to generate high resolution and fidelity samples.
- Disadvantages: GANs can be difficult to stabilize and may suffer from mode collapse. They are also prone to generating artifacts and may require careful tuning to produce high-quality samples.
- Flow-based Models:
- Advantages: Flow-based models can generate high-quality and diverse samples and can be used for tasks such as density estimation and image synthesis. They are also computationally efficient and allow for efficient sampling and likelihood computation.
- Disadvantages: Flow-based models may be difficult to train and may require careful tuning to achieve good performance. They may also suffer from overfitting and may be sensitive to the choice of architecture and hyperparameters.
- Diffusion Models:
- Advantage: One of the main advantages of diffusion models is their ability to generate high-quality images and videos with a wide range of resolutions and content. They are particularly effective at generating images and videos with complex spatial and temporal patterns, and can generate diverse and realistic samples that are similar to the original data.
- Disadvantage: One potential disadvantage of diffusion models is that they can be computationally expensive to train, particularly for high-resolution images and videos. The training process involves a series of diffusion steps, which can be time-consuming and memory-intensive. In addition, the quality of the generated samples may be sensitive to the choice of hyperparameters and the model’s architecture, which may require careful tuning and experimentation.
Nevertheless, the choice of generative model depends on the specific application and the characteristics of the data. Each type of generative model has its own advantages and disadvantages, and researchers and practitioners should carefully consider the trade-offs when choosing a model for a particular task.
How to implement generative models
- TensorFlow: TensorFlow is an open-source library for machine learning and deep learning. It has built-in support for many types of generative models, including autoencoders, variational autoencoders, GANs, and flow-based models. TensorFlow is widely used in industry and academia, and has a large and active community of developers and users.
- PyTorch: PyTorch is another popular open-source library for machine learning and deep learning. Like TensorFlow, it has built-in support for many types of generative models, and is widely used in industry and academia. PyTorch is known for its ease of use and flexibility, and has a growing community of developers and users.
- Keras: Keras is a high-level neural networks API written in Python. It is built on top of TensorFlow and provides a simple and intuitive interface for building and training neural networks, including generative models. Keras is easy to use and has a large and active community of developers and users.
- OpenAI’s GPT-3: OpenAI’s GPT-3 is a powerful language model that can generate natural language text. It is a cloud-based platform that can be accessed through an API, and can be used to generate text in a wide range of styles and formats. GPT-3 has shown impressive results in generating text for a variety of applications, including chatbots, content creation, and text completion.
These are just a few examples of the many libraries and platforms available for implementing generative models in Python. The choice of library or platform depends on the specific requirements of the project and the user’s familiarity with the tools.
Conclusion
In conclusion, generative models are a type of machine learning model that can learn to generate new data that is similar to the data it was trained on. There are several types of generative models, including autoencoders, variational autoencoders, generative adversarial networks (GANs), and flow-based models.
Autoencoders are neural networks that can learn to compress and reconstruct input data, while VAEs add a probabilistic layer to the standard autoencoder architecture. GANs are neural networks that consist of two parts, a generator and a discriminator, and can generate highly realistic and diverse samples. Flow-based models use a sequence of invertible transformations to transform a simple distribution into a more complex distribution.
Each type of generative model has its own advantages and disadvantages, and the choice of model depends on the specific requirements of the project and the characteristics of the data. Some of the popular libraries and platforms for implementing generative models in Python include TensorFlow, PyTorch, Keras, and OpenAI’s GPT-3.
Overall, generative models are a powerful and promising area of research that has already demonstrated impressive results in generating realistic and diverse data samples. They have a wide range of applications in computer vision, natural language processing, and many other areas, and are an active and exciting area of ongoing research.
Stay tune for the coding example for generative models 🙂
A presto